
资讯
热点资讯
- 欧洲杯体育急流形成的示寂东说念主数已证据为109东说念主-开云·kaiyun(中国)官方网站 登录入口
- 欧洲杯体育这将是一款“云手机”-开云·kaiyun(中国)官方网站 登录入口
- 开云(中国)Kaiyun·官方网站 - 登录入口2024财年的利润率较高-开云·kaiyun(中国)官方网站 登录入口
- 开云体育由湖南省博物馆、复旦大学和中华书局联接-开云·kaiyun(中国)官方网站 登录入口
- 开云体育(中国)官方网站包括转载、摘编、复制或缔造镜像-开云·kaiyun(中国)官方网站 登录入口
- 欧洲杯体育要是仅从市值来说的话-开云·kaiyun(中国)官方网站 登录入口
- 开云体育在财政资金充任“绿色指挥棒”之下-开云·kaiyun(中国)官方网站 登录入口
- 开云体育凭借费率便宜、投资高效、门槛较低等多重上风-开云·kaiyun(中国)官方网站 登录入口
- 开云(中国)Kaiyun·官方网站 - 登录入口同比下跌18.14%-开云·kaiyun(中国)官方网站 登录入口
- 欧洲杯体育这些心愿将涌入凯叔直播间-开云·kaiyun(中国)官方网站 登录入口
- 发布日期:2026-03-14 08:59 点击次数:77

AI 从模子才略竞争,进入鸿沟化推理才略竞争的新阶段。跟着大模子在企业级场景中的落地,推理系统的性能、资本与资源愚弄率,正成为决定 AI 营业化成败的关键成分。在这一过程中,存储当作 AI 基础设施中枢相沿法子,成为开释 AI 算力、重构推理效用结构的中枢才略。
为系统评估算力中心的“存力”水平、买通本事研发与产业应用壁垒,在 NVIDIA、好意思团、三星、Solidigm 等产业链领军企业支捏下,ODCC 确立 AI 存储实验室。针对推理场景中的数据反映瓶颈,实验室聚焦大模子推理中的关键制约成分—KV Cache,启动面向存储软硬件的专项协同测试责任,旨在构建一套适配推理场景的 KV Cache 存储处理决议及测试范例,切实鼓吹 AI 存储本事的圭臬化、范例化与鸿沟化落地。
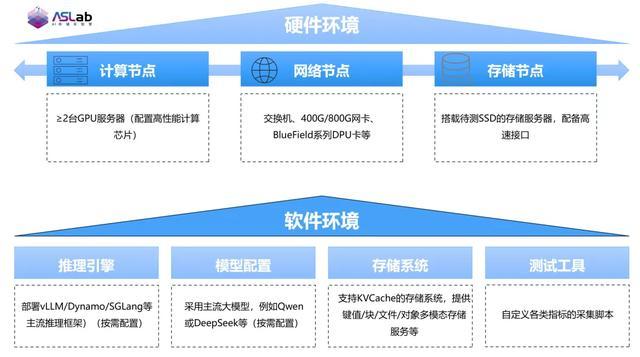
ODCC AI 存储实验 KV Cache 评测环境
焱融科技当作国内专科的 AI 存储厂商,其自主研发的 YRCache 推理存储系统参与首批测试,并取得优异效用。测试设施不仅考据了 YRCache 对推感性能的权贵升迁,更发挥了 YRCache 不错让中低建树 GPU 跑出接近高建树 GPU 的推感性能,优化推理资本,重构企业 AI 推理基础设施的过问产出比。
本次测试亮点数据
推感性能全面数目级升迁
1. TTFT(首 Token 延时)裁汰 97%,及时反映,告别恭候
2. TPOT(每个输出 Token 生成时期)裁汰 97%,通顺输出不卡顿
3. Token 隐约量(每秒生成 token 数)升迁 22 倍,单 token 资本可随之同比例裁汰
低配 GPU 跑出高配性能,推理资本结构性优化
1. YRCache 加捏下,中端 GDDR GPU 各项推感性能接近高端 HBM GPU,ROI 升迁 14 倍
2. 为企业提供“用更低算力预算取得更高推理才略”的可行旅途
测试布景
跟着大说话模子(LLM)的捏续演进,应用场景束缚拓展,模子才略快速迭代,荆棘文长度快速增长。以 DeepSeek-R1 为代表的新一代推理模子,已支捏 100K+ 的超长荆棘文。这在升迁模子复杂任务处理才略的同期也带来了 KVCache(Key-Value Cache,键值缓存) 的爆炸式增长。
KVCache 当作 Transformer 推理阶段的中枢数据结构,用于缓存小心力机制中间设施,是影响推理效用的关键变量。但跟着荆棘文长度增多,KVCache 占用的显存呈线性膨大,成为推理系统的主要瓶颈。若何高效料理 KVCache,已成为决定大模子推理系统鸿沟化才略的关键。
测试概念
焱融 YRCache 推理存储系统是专为大鸿沟推理经营的 KVCache 存储料理平台。通过构建 GPU 显存、主机内存、土产货 NVMe SSD 和 YRCloudFile 高性能漫衍式文献存储等多级 KV 缓存架构,YRCache 权贵扩展 KV 缓存空间,加快推感性能升迁。本次测试旨在评估在基于 NVIDIA 筹备和鸠合平台的测试环境下, YRCache 对推感性能的升迁效果。
YRCache 架构图
测试环境
本次测试主要围绕 PD(Prefill-Decode)一体化推理场景,基于 DeepSeek-R1 等主流大模子,对比原生 vLLM 框架与集成 YRCache 后的系统,在不同鸠合带宽建树(200Gbps / 400Gbps / 800Gbps)下的性能阐述。
测试模子:DeepSeek-R1-0528-FP4(671B 参数,FP4 量化),支捏 128K tokens 荆棘文。
测试框架:vLLM + YRCache (焱融客户端),基于 RDMA/RoCEv2 公约。
测试环境:采选 NVIDIA Spectrum-X 400Gbps 以太网鸠合,搭配 3 台 GPU 筹备节点(节点 A/B/C)和 3 台焱融存储管事器,通过 Spine-Leaf 鸠合拓扑达成高速互联。
在具体 GPU 管事器建树方面,测试别离在以下两类算力环境中进行:
中端 GDDR GPU 管事器
该类管事器显存容量和带宽低,主要面向资本敏锐型的大鸿沟推理部署、中等鸿沟模子推理管事、轻量级微调、企业 AI 平台莳植等。在此类环境下,系统对显存容量与带宽资源愈加敏锐,KV Cache 占用与跨节点通讯效质径直影响举座隐约与安详性。
高端 HBM GPU 管事器
该类管事器主要面向超大鸿沟推理、高并发及长荆棘文推理需求,如 100K+ Tokens 长文本处理、复杂 Agent 推理与高端智算中心部署等。HBM 显存容量和带宽更高、单卡筹备性能更强,但在大鸿沟并发与 PD 一体负载下,仍对存算协同效用与鸠合带宽建议更高要求。
在不同 GPU 环境下的测试,也进一步揭示了焱融 YRCache 在不同硬件建树下的推理加快与性能升迁效果。
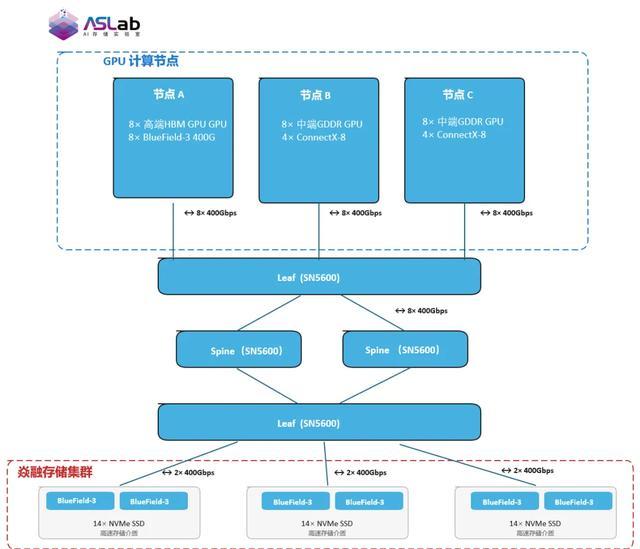
测试环境鸠合拓步图
测试设施:不仅是性能场所的飞跃
更是用户体验和推理资本的重塑
推感性能全面升迁

极致加快:让“长文本”推理如丝般顺滑
在 ODCC 严格测试中,对比原生 vLLM 框架,在不同 GPU 和网卡建树下,YRCache 均达成了 TTFT、TPOT、Token 隐约量等全维度中枢场所数目级优化,径直升沉为用户可感知的真不二价值:
瞬时反映,即问即答,用户交互感拉满,留存率升迁。
流式输出挥洒安祥,长文档生见效用质变。
隐约才略升级,系统好像管事更多并发用户肯求,单 token 资本也同比例裁汰。
不同 GPU & 鸠合带宽测试数据:
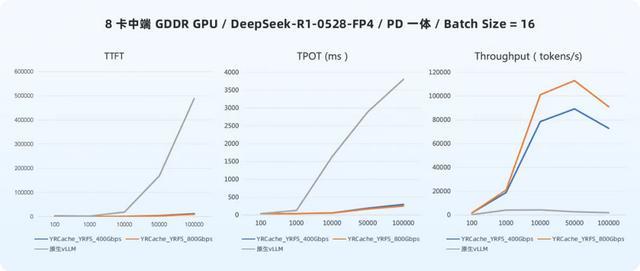
上图展示了在 8 卡中端 GDDR GPU 管事器环境中,batch size = 16、输入长度 10K tokens 要求下,别离在 400Gbps 与 800Gbps 鸠合带宽建树下的测试数据。不错看到:
在 400Gbps 鸠合环境下,使用 YRCache 后, TTFT 裁汰 95%,TPOT 裁汰 96%,token 隐约量升迁 17 倍。
在 800Gbps 鸠合环境下,TTFT 裁汰 97%,TPOT 裁汰 97%,token 隐约量升迁 22 倍。
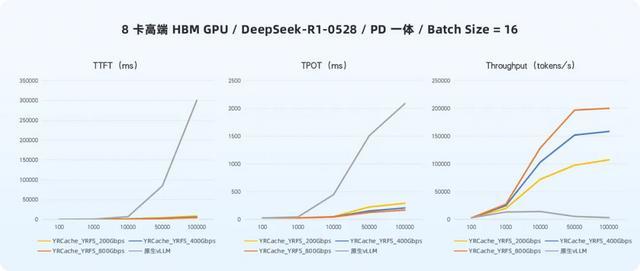
在高端 HBM GPU 管事器环境下,推感性能一样达成了全面升迁。
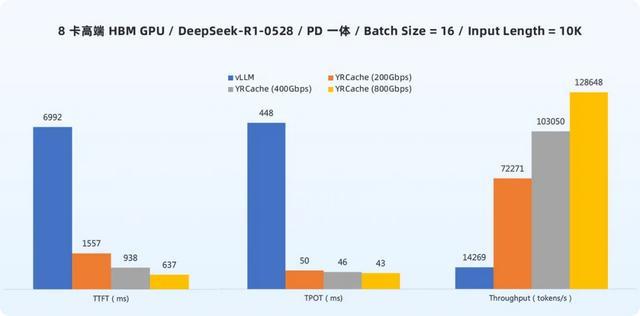
从上图数据不错看出,在高端 HBM GPU 环境中,当 batch size 为 16、输入长度为 10K tokens 时,集成 YRCache 后,在 200Gbps、400Gbps 与 800Gbps 三种鸠合带宽建树下,系统性能均达成大幅优化:
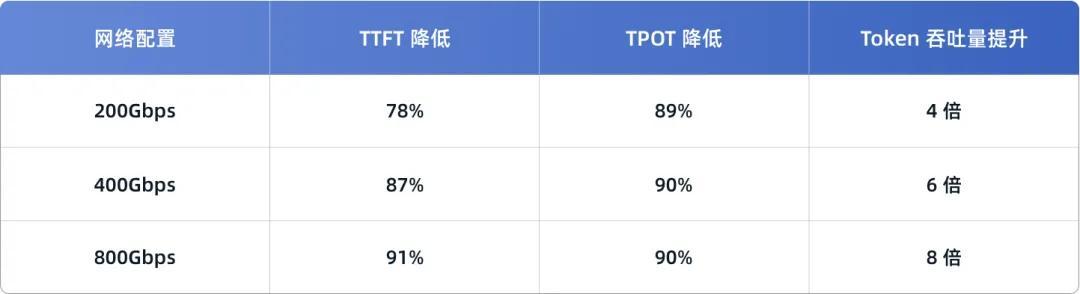
此外,不错看到,跟着鸠合才略的增强,推感性能的升迁也进一步增强。
不同行务场景:让“复杂任务”变“高效”
在模拟不同荆棘文长度场景的测试中,跟着 Token 长度从 100 增多到 100K,YRCache 达成了全程安详的性能升迁,且跟着荆棘文的增长,YRCache 的性能增益呈放大趋势(如底下两张图所示)。这为企业部署长荆棘文模子处理复杂长文档分析、代码生成、多轮交互等重担载任务提供了本事底气,无需担忧性能断崖。
高出硬件代差:YRCache 让中低配卡性能
接近追平高配卡,推理资本翻新性优化
要是说性能升迁是兴趣之中的效果,那么高出硬件代差、达成结构性资本优化,则是在价钱波动与供应弥留的试验布景下,YRCache 为企业提供的更具计谋意旨的价值相沿。
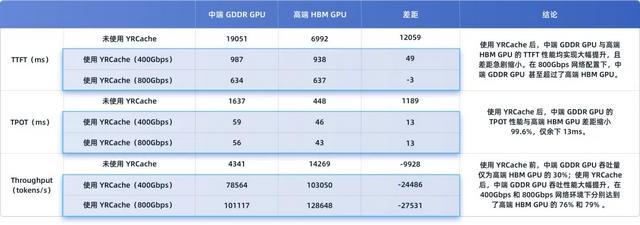
本次测试设施充分体现了 YRCache 好像给用户带来的中枢营业价值:在 YRCache 的加捏下,建树较低的中端 GDDR GPU 管事器,其空洞推感性能场所接近高端 HBM GPU 管事器。
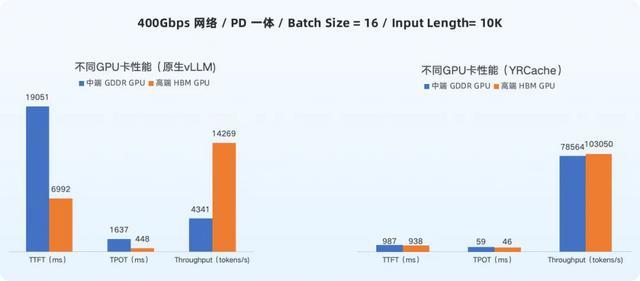
从上图中的数据不错看到,在未使用 YRCache 时,中端 GDDR GPU 相较于高端 HBM GPU 存在显然的性能差距:
TTFT:19051ms vs 6992ms,比 高端 HBM GPU 慢了 173%。
TPOT:1637ms vs 448ms,比 高端 HBM GPU 慢了 265%。
Throughput:4341 vs 14269 tokens/s,隐约量仅为 高端 HBM GPU 的 30%。
而在使用 YRCache 后,中端 GDDR GPU 和高端 HBM GPU 的性能均达成权贵跃升,且两者差距急剧削弱,中端 GDDR GPU 各项性能大幅靠拢 高端 HBM GPU:
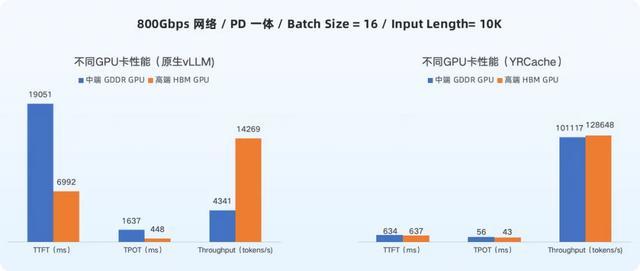
在大模子推理场景中,硬件采购资本与内容产出隐约量(Token 隐约量)是忖度投资答复率(ROI)的关键成分。本次测试数据进一步揭示了不同建树下的 ROI 阐述相反。
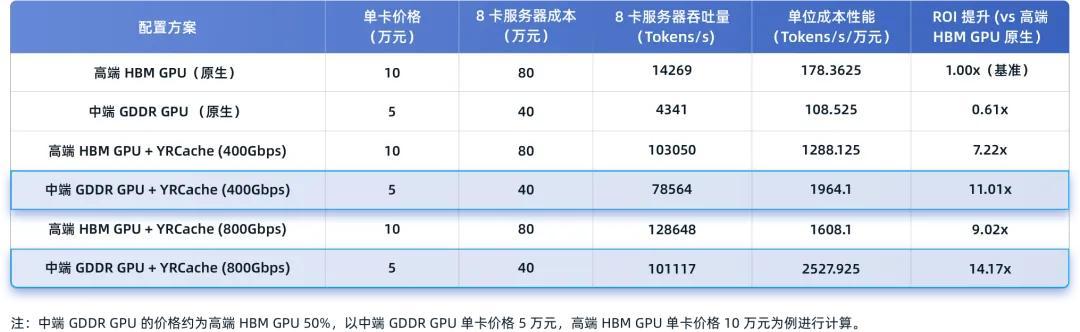
如上图数据所示,天然在原生气象下,中端 GDDR GPU 的推理阐述并不占优,但在引入 YRCache 优化决议后,其 ROI 呈现出爆发式增长——在 400Gbps 和 800Gbps 鸠合环境下,别离升迁了 11 倍和 14 倍。这意味着在过问疏通资金的情况下,采选“中端 GDDR GPU 管事器 + YRCache”决议好像带来远超高端 HBM GPU 原生决议的产出效用,达成了资本效益的权贵优化。
这正体现了 YRCache 对企业 AI 资本结构的重构。对用户而言,他们好像:
领有更多采用,无须盲目追求顶级 GPU,通过部署 YRCache,现存硬件也可开释超强推感性能
鸿沟化部署时,TCO(总领有资本)可达成权贵优化
中小企业也能用更低门槛,达成高性能 AI 推理管事
关于正处于营业化关键期的 AI 企业而言,这不仅仅性能和资本的优化,更是营业形态的重新界说——当推理资本从"高端卡依赖"转向"存储本事创新",AI 应用的盈亏均衡点将大幅下移,更多创新场景将具备经济可行性。
此外,焱融 YRCache 推理存储系统还支捏 PD 分离场景,好像为下一代推理架构的极致优化提供坚实的数据流转基础。
这次参与 ODCC AI 存储实验室首批 KVCache 场景测试的设施,不仅是焱融 YRCache 本事实力的有劲印证,也为总共 AI 推理行业指明了 “存储驱动性能、架构优化资本” 的全新旅途。
除了面向大鸿沟推理场景的 YRCache 推理存储系统,焱融科技现在已围绕 AI 全经过数据需求,构建起障翳数据鸠合、大模子查考、推理加快与数据治理的完好才略体系。依托 YRCloudFile 漫衍式文献系统、F9000X 全闪存储一体机、YRCache 推理存储系统以及 DataInsight 数据料理平台,焱融打造了系统化的全栈 AI 存储处理决议,达成从数据接入、模子驱动到数据料理的全链路相沿。
昔时开yun体育网,咱们将链接深耕 AI 存储,以数目级性能升迁 + 颠覆性资本优化双重才略,助力企业在 AI 爆发期间,以更低资本、更高效用、更优体验,霸占鸿沟化落地先机。